1. 막대 차트
- 각 값들의 비교를 할때 시각화
- 시각화 영역에서 가장 많이 쓰는 차트
# 데이터 준비
categories = ['A', 'B', 'C', 'D']
values = [10, 20, 15, 25]
# 막대 그래프 그리기
plt.bar(categories, values)
# 그래프 보여주기
plt.show()
2.산점도 (스캐터 차트)
- 두 변수 간의 관계를 시각적으로 표현하는 데 사용되는 그래프
- 각 데이터 포인트는 두 변수의 값을 좌표로 하여 점으로 표현
- 이를 통해 두 변수 간의 상관 관계, 패턴, 이상치 등을 파악할 수 있음
#산점도 그리기
np.random.seed(0)
n = 50
x = np.random.rand(n)
y = np.random.rand(n)
plt.scatter(x, y)
plt.show()
# 3차원 산점도
from mpl_toolkits.mplot3d import Axes3D
import matplotlib.pyplot as plt
import numpy as np
n = 100
xmin, xmax, ymin, ymax, zmin, zmax = 0, 20, 0, 20, 0, 50
cmin, cmax = 0, 2
xs = np.array([(xmax - xmin) * np.random.random_sample() + xmin for i in range(n)])
ys = np.array([(ymax - ymin) * np.random.random_sample() + ymin for i in range(n)])
zs = np.array([(zmax - zmin) * np.random.random_sample() + zmin for i in range(n)])
color = np.array([(cmax - cmin) * np.random.random_sample() + cmin for i in range(n)])
fig = plt.figure(figsize=(6, 6))
ax = fig.add_subplot(111, projection='3d')
ax.scatter(xs, ys, zs, c=color, marker='o', s=15, cmap='Greens')
plt.show()
3. 히스토그램(histogram)
- 연속형 데이터의 분포를 한눈에 파악하는 데 유용
- 데이터를 일정한 구간(구간의 범위)에 나누고, 각 구간에 속하는 데이터의 개수를 막대의 높이로 표시
import matplotlib.pyplot as plt
weight = [68, 81, 64, 56, 78, 74, 61, 77, 66, 68, 59, 71,
80, 59, 67, 81, 69, 73, 69, 74, 70, 65]
plt.hist(weight)
plt.show()
4. 파이 차트
- 데이터의 전체를 원(또는 파이)으로 나타내고, 각 범주가 차지하는 상대적 비율을 부채꼴 모양으로 표현
-범주의 상대적인 비율을 직관적으로 비교할 수 있으며, 어떤 범주가 더 크거나 작은지 빠르게 이해할 수 있음
# 데이터 준비
sizes = [30, 40, 20, 10]
labels = ['A', 'B', 'C', 'D']
# 파이 차트 그리기
plt.pie(sizes, labels=labels)
# 그래프 보여주기
plt.show()
# 도넛 차트
ratio = [34, 32, 16, 18]
labels = ['a', 'b', 'c', 'd']
wedgeprops = {'width': 0.7, 'edgecolor': 'k', 'linewidth': 1} #도넛형 파이차트를 만들기 위한 너비 설정 (1보다 작으면 가운데가 뚫림)
plt.pie(ratio, labels=labels, autopct="%.1f%%", explode=[0, 0, 0, 0], colors=['red', 'yellow', 'green', 'blue'], wedgeprops=wedgeprops)
plt.show()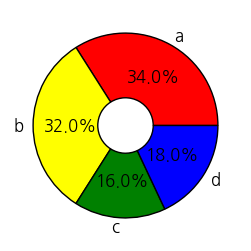
5. 히트맵
- 데이터의 값을 색상으로 표현하여 시각적으로 분석하기 쉽게 만드는 데이터 시각화 기법
- 일반적으로 2차원 배열 형태의 데이터를 다루며, 각 값에 따라 색상이 지정됨
- 이를 통해 데이터의 분포나 패턴을 한눈에 파악할 수 있음
# 히트맵 시각화
arr = np.random.standard_normal((30, 40))
plt.matshow(arr)
plt.show()
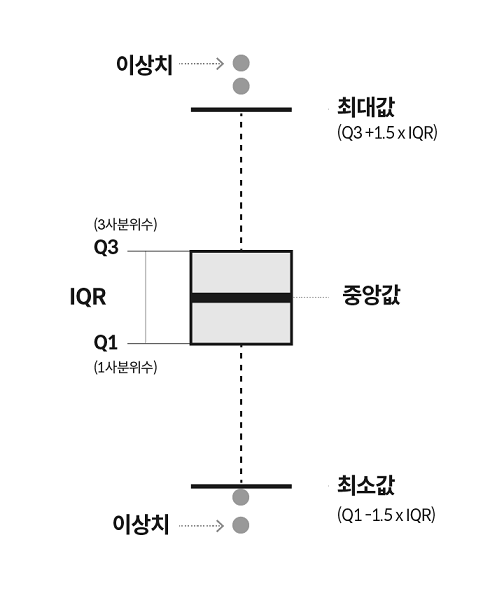
6.박스플롯
- 데이터의 분포와 이상치를 동시에 보여주면서 서로 다른 데이터군을 쉽게 비교할 수 있는 데이터 시각화 유형
-로우 데이터를 그대로 사용하지 않고 다섯숫자요약(Five-Number Summary)이라는 통계학적 개념으로 데이터를 가공하여 시각화
* IQR은 Interquartile Range의 약자로, 사분위범위를 의미
# 박스 플롯
# 1. 기본 스타일 설정
plt.style.use('default')
plt.rcParams['figure.figsize'] = (4, 3)
plt.rcParams['font.size'] = 12
# 2. 데이터 준비
np.random.seed(0)
data_a = np.random.normal(0, 2.0, 1000)
data_b = np.random.normal(-3.0, 1.5, 500)
data_c = np.random.normal(1.2, 1.5, 1500)
# 3. 그래프 그리기
fig, ax = plt.subplots()
ax.boxplot([data_a, data_b, data_c], notch=True, whis=2.5)
ax.set_ylim(-10.0, 10.0)
ax.set_xlabel('Data Type')
ax.set_ylabel('Value')
plt.show()
7. 바이올린 플롯
- 데이터의 밀도를 나타내며, 폭이 넓을수록 해당 값의 데이터 빈도가 높음을 의미
- 박스 플롯 (Box plot)과 비슷하지만 더 실제에 가까운 분포를 알 수 있다는 장점이 있음
# 1. 기본 스타일 설정
plt.style.use('default')
plt.rcParams['figure.figsize'] = (4, 3)
plt.rcParams['font.size'] = 12
# 2. 데이터 준비
np.random.seed(0)
data_a = np.random.normal(0, 2.0, 1000)
data_b = np.random.normal(-3.0, 1.5, 500)
data_c = np.random.normal(1.2, 1.5, 1500)
# 3. 그래프 그리기
fig, ax = plt.subplots()
violin = ax.violinplot([data_a, data_b, data_c], positions=[2, 3, 4])
ax.set_ylim(-10.0, 10.0)
ax.set_xticks([1, 2, 3, 4, 5])
ax.set_xlabel('Data Type')
ax.set_ylabel('Value')
plt.show()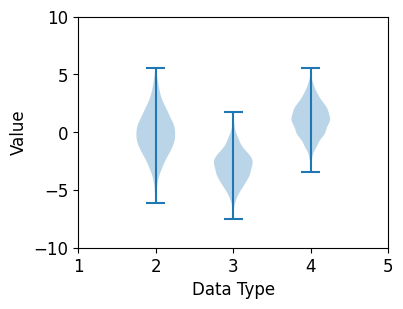
'Python' 카테고리의 다른 글
| Pygwalker - Jupyter Notebook 환경에서 반응형 시각화하기 (1) | 2025.08.28 |
|---|---|
| Matplotlib 한글이 깨져서 나올 때 (0) | 2025.06.17 |
| Matplotlib을 활용한 데이터 시각화 (0) | 2025.06.17 |