
태블로 머신러닝: 클러스터링과 예측은 어떻게 작동할까?
태블로(Tableau)는 강력한 데이터 시각화 툴이지만, 데이터를 기반으로 클러스터링과 예측 분석도 가능하도록 지원합니다. 이 글에서는 클러스터링과 예측 모델이 어떤 데이터를 기반으로 작동하며, 이를 구현할 때 무엇을 고려해야 하는지 자세히 알아보겠습니다.
1. 클러스터링(Clustering): 데이터의 군집화
클러스터링은 데이터를 특성에 따라 비슷한 그룹으로 나누는 머신러닝 기법입니다. 태블로에서 클러스터링은 비지도 학습(Unsupervised Learning) 방식으로 작동하며, 주로 다음과 같은 데이터 특성을 기반으로 그룹을 형성합니다:
기준 데이터
• 수치 데이터(Numerical Data): 매출, 방문자 수, 제품 가격 등 연속적인 값
• 범주형 데이터(Categorical Data): 지역, 고객 유형, 제품 카테고리 등 그룹화 가능한 값
기본 알고리즘
태블로의 클러스터링은 K-평균(K-Means) 알고리즘을 사용합니다. 이 알고리즘은 데이터를 사용자가 지정한 군집(K) 수로 나누며, 각 군집이 내부적으로 얼마나 유사한지를 기반으로 그룹화합니다.
예:
• 고객 데이터를 클러스터링하여 VIP 고객 그룹을 식별
• 판매 데이터를 클러스터링하여 지역별 판매 패턴 분석
사용자의 데이터 선택 기준
• 군집화를 위해서는 유사성을 계산할 특성(필드) 을 선택해야 합니다.
• 수치 데이터와 범주형 데이터를 조합할 경우, 태블로는 자동으로 스케일 조정을 수행하여 분석의 정확성을 유지합니다.
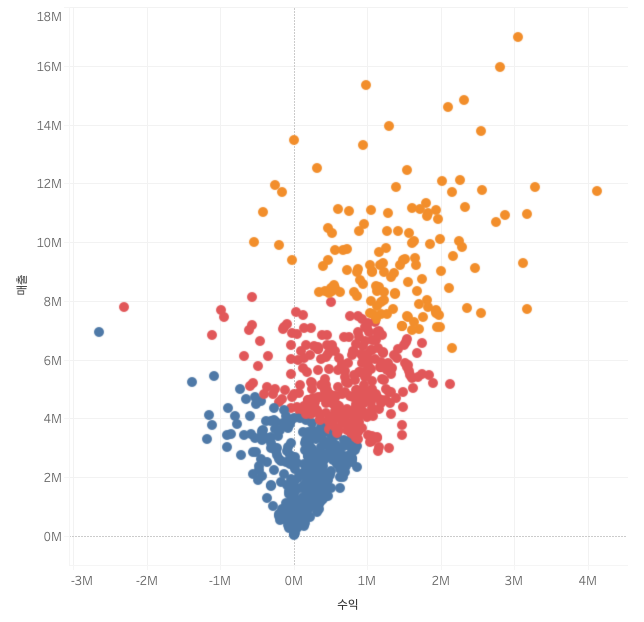
2. 예측(Forecasting): 미래 데이터 추정
예측은 주어진 데이터를 바탕으로 미래의 값을 추정하는 데 사용됩니다. 태블로에서 예측은 주로 시계열 데이터를 기반으로 작동하며, 특정 패턴이나 트렌드를 식별하는 데 중점을 둡니다.
기준 데이터
• 시간 데이터(Time Data): 일별, 주별, 월별 등의 시간에 따라 수집된 데이터.
• 연속형 변수(Continuous Variables): 시간에 따라 변동하는 값(예: 매출, 트래픽, 수익).
기본 알고리즘
태블로의 예측 기능은 ARIMA(Autoregressive Integrated Moving Average) 모델을 사용하여 미래 값을 추정합니다. 이 모델은 데이터의 계절성(Seasonality) 과 추세(Trend) 를 자동으로 감지하고 적용합니다.
예:
• 월별 매출 데이터를 사용하여 다음 달 매출을 예측
• 주간 트래픽 데이터를 분석해 다음 주 방문자 수를 추정

3. 클러스터링과 예측의 데이터 선택 기준 비교
기능 데이터 요구 사항 사용 사례 선택 시 주의점
클러스터링 : 여러 특성 필드 선택 필요 고객 세분화, 제품 그룹화 특성이 적절히 선택되지 않으면 결과 해석이 어려움
예측 : 과거 데이터의 충분성 매출 예측, 수요 예측 과거 데이터가 부족하거나 계절성이 크면 정확도 감소
4. 태블로에서 클러스터링과 예측 구현하기
클러스터링
1. 데이터 준비: 클러스터링에 사용할 필드를 선택합니다(예: 매출, 방문자 수, 지역 등).
2. 분석 메뉴 사용: “분석(Analysis)” 패널에서 “클러스터 추가(Add Clusters)“를 선택합니다.
3. 클러스터 수 설정: 군집 수(K)를 지정하면 태블로가 자동으로 클러스터를 생성합니다.
4. 결과 확인: 각 데이터 포인트가 어떤 클러스터에 속하는지 시각적으로 확인합니다.
예측
1. 데이터 준비: 시간 데이터를 포함한 연속형 데이터를 준비합니다(예: 날짜, 매출)
2. 시계열 시각화: 차트를 시간 기준으로 정렬합니다.
3. 예측 추가: “분석(Analysis)” 패널에서 “예측 추가(Add Forecast)“를 클릭하면 태블로가 자동으로 적합한 모델을 적용합니다.
4. 신뢰 구간 분석: 예측된 값의 신뢰 구간(Confidence Interval)을 통해 예측의 정확도를 검토합니다.
5. 클러스터링과 예측 구현 시 주의할 점
1. 데이터 품질: 결측치, 이상치가 많으면 결과가 왜곡될 수 있으므로 데이터 클리닝이 중요합니다.
2. 변수 선택: 예측이나 클러스터링에 적합한 변수를 선택해야 합니다. 부적절한 변수가 포함되면 분석 결과가 왜곡될 수 있습니다.
3. 정규화: 수치 데이터 간의 스케일이 크게 다를 경우, 정규화나 표준화를 고려해야 합니다.
결론
태블로에서 클러스터링과 예측 분석은 데이터의 특성과 알고리즘의 이해를 바탕으로 작동합니다. 클러스터링은 데이터의 유사성을 기반으로 그룹을 형성하고, 예측은 시간 데이터를 통해 미래를 추정합니다. 데이터 품질과 선택된 변수는 결과의 정확도에 중요한 영향을 미치며, 태블로의 자동화 기능을 활용하면 복잡한 분석도 손쉽게 구현할 수 있습니다.
도움이 되셨다면 공감과 구독, 댓글 부탁 드립니다 : )
'Tableau > Tableau Desktop' 카테고리의 다른 글
| Tableau Desktop - Amazon S3 버킷 연결 (0) | 2025.06.19 |
|---|---|
| Tableau로 덤벨 차트 만들기 (0) | 2025.05.12 |
| 주소 데이터 위경도 좌표로 변환하여 태블로로 시각화하기 (0) | 2024.10.03 |
| Python에서 Tableau hyper 파일 열기 (1) | 2024.10.01 |